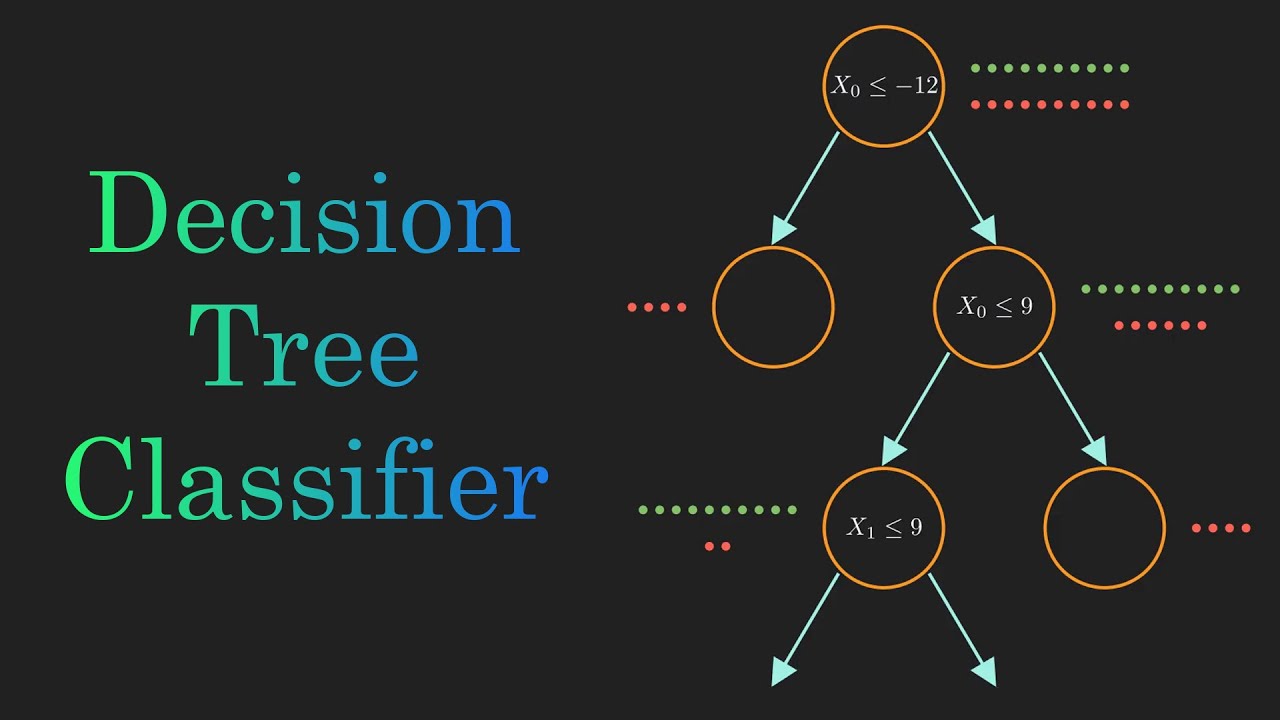
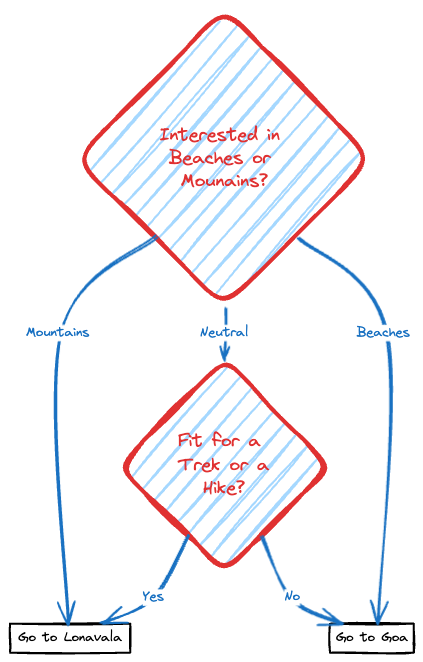
Assume that you're a traveller planning your next weekend getaway and have two amazing options: A relaxing beach trip to Goa or a thrilling mountain adventure in Lonavala. But, how do you decide one way or the other? This is where Decision Trees come in. They are like flowcharts, visually representing all the scenarios. Let's look deeper into this example.
Our first question would be if the person is interested in beaches or mountains.
Another decisive question could be if the person is fit for a trek or a hike.
Let's look at a visual representation of how a Decision Tree could help in this.
Shown above is a standard representation of a hypothetical situation but there's a lot of math that goes into it. Ready for it? Let's get right in!
Decision Tree Variants The decision tree is not restricted to just classification or regression. There is a separate arithmetic calculation in each node for each of these variants. The variants are:
Decision Tree Classifier Decision Tree Regressor The Decision Tree evaluates each given feature to find the most relevant one and equates the results for that specific feature first. This is done until all the features are evaluated and the leaf node is encountered. A leaf node is defined as a node to which there are no Childs. This node is used for prediction. As for the tuning, the depth of the decision tree could be restricted, meaning that longest path between the root node and a leaf node is restricted to a specified number.
Decision Tree Classifier The decision tree classifier is very similar to a flow chart. Each node of decision tree has certain evaluations that go into it. There are two different ways to do this. One is Information Gain method, and the other is Gini Index method. Let's look at the steps involved in building these and the Mathematics and Statistics behind it.
Step 1: Calculate the Entropy of entire Dataset Entropy is defined as randomness or uncertainty in the given data or situation. First step in building the decision tree classifier is to calculate the entropy of the entire dataset. This can be done by calculating the entropy of the label or the target column. The formula for this is:
E n t r o p y o f D a t a s e t = − ∑ c l a s s = 1 n p ( c l a s s ) l o g 2 ( p ( c l a s s ) ) Entropy,of,Dataset =-sum_{class=1}^{n}p(class) , log_2,(p(class)) E n t ro p y o f D a t a se t = − c l a ss = 1 ∑ n p ( c l a ss ) l o g 2 ( p ( c l a ss )) W h e r e p ( c l a s s ) = N u m b e r o f s a m p l e s c o r r e s p o n d i n g t o t h e c l a s s T o t a l n u m b e r o f s a m p l e s Where;p(class) = �rac{Number,of,samples,corresponding,to,the,class}{Total,number,of,samples} Wh ere p ( c l a ss ) = T o t a l n u mb er o f s am pl es N u mb er o f s am pl es corres p o n d in g t o t h e c l a ss Step 2: Calculate Entropy of each Feature Column When calculating entropy of each feature column, we need to first calculate entropy for each unique value in the selected feature column using the following equation. Select all the rows corresponding to selected value and calculate entropy with respect to those rows.
E n t r o p y o f U n i q u e V a l u e = ∑ c l a s s = 1 n p ( c l a s s ) l o g 2 ( p ( c l a s s ) ) Entropy,of,UniqueValue =sum_{class=1}^{n}p(class) , log_2,(p(class)) E n t ro p y o f U ni q u e Va l u e = c l a ss = 1 ∑ n p ( c l a ss ) l o g 2 ( p ( c l a ss )) W h e r e p ( c l a s s ) = N u m b e r o f s a m p l e s c o r r e s p o n d i n g t o t h e c l a s s a n d s e l e c t e d f e a t u r e v a l u e T o t a l n u m b e r o f s a m p l e s Where;p(class) = �rac{Number,of,samples,corresponding,to,the,class,and,selected,feature,value}{Total,number,of,samples} Wh ere p ( c l a ss ) = T o t a l n u mb er o f s am pl es N u mb er o f s am pl es corres p o n d in g t o t h e c l a ss an d se l ec t e d f e a t u re v a l u e After calculating the entropy for each unique value in the feature column, next step is to calculate the entropy of the feature column using the following arithmetic equation:
E n t r o p y o f F e a t u r e = ∑ U n i q u e V a l = 1 n p ( U n i q u e V a l ) . E n t r o p y o f U n i q u e V a l Entropy,of,Feature = sum_{UniqueVal=1}^n p(UniqueVal) . Entropy,of,UniqueVal E n t ro p y o f F e a t u re = U ni q u e Va l = 1 ∑ n p ( U ni q u e Va l ) . E n t ro p y o f U ni q u e Va l W h e r e p ( c l a s s ) = N u m b e r o f s a m p l e s c o r r e s p o n d i n g t o t h e U n i q u e V a l T o t a l n u m b e r o f s a m p l e s Where;p(class) = �rac{Number,of,samples,corresponding,to,the,UniqueVal}{Total,number,of,samples} Wh ere p ( c l a ss ) = T o t a l n u mb er o f s am pl es N u mb er o f s am pl es corres p o n d in g t o t h e U ni q u e Va l Repeat this process for each feature column.
Information Gain is a measure used to determine which feature column is to be selected next.
I G ( T a r g e t , F e a t u r e ) = E n t r o p y o f D a t a s e t − E n t r o p y o f F e a t u r e IG(Target,,Feature) = Entropy,of,Dataset - Entropy,of,Feature I G ( T a r g e t , F e a t u re ) = E n t ro p y o f D a t a se t − E n t ro p y o f F e a t u re The value with highest Information Gain is selected to be the root node or the next node.
Working Example Now let's look at how this works in practice. Consider the following dataset:
The Entropy of the entire dataset is:
E n t r o p y ( P l a y F o o t b a l l ) = − 9 14 l o g 2 9 14 − 5 14 l o g 2 5 14 = 0.94 Entropy(Play,Football) = -�rac{9}{14} log_2�rac{9}{14} - �rac{5}{14} log_2�rac{5}{14} = 0.94 E n t ro p y ( Pl a y F oo t ba ll ) = − 14 9 l o g 2 14 9 − 14 5 l o g 2 14 5 = 0.94 Next step is to calculate Entropy for each feature column.
For Weather: There are three unique values: Sunny, Rainy and Cloudy E n t r o p y o f S u n n y = − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 = 0.97 Entropy,of,Sunny=-�rac{2}{5}log_2�rac{2}{5}-�rac{3}{5}log_2�rac{3}{5} = 0.97 E n t ro p y o f S u nn y = − 5 2 l o g 2 5 2 − 5 3 l o g 2 5 3 = 0.97 E n t r o p y o f R a i n y = − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 = 0.97 Entropy,of,Rainy=-�rac{3}{5}log_2�rac{3}{5}-�rac{2}{5}log_2�rac{2}{5} = 0.97 E n t ro p y o f R ain y = − 5 3 l o g 2 5 3 − 5 2 l o g 2 5 2 = 0.97 E n t r o p y o f C l o u d y = − 4 4 l o g 2 4 4 − 0 4 l o g 2 0 4 = 0 Entropy,of,Cloudy=-�rac{4}{4}log_2�rac{4}{4}-�rac{0}{4}log_2�rac{0}{4} = 0 E n t ro p y o f Cl o u d y = − 4 4 l o g 2 4 4 − 4 0 l o g 2 4 0 = 0 I G ( W e a t h e r ) = E n t r o p y ( P l a y F o o t b a l l ) − 5 14 E n t r o p y ( S u n n y ) − 5 14 E n t r o p y ( R a i n y ) − 4 14 E n t r o p y ( C l o u d y ) IG(Weather) = Entropy(Play Football) - �rac{5}{14} Entropy(Sunny) - �rac{5}{14} Entropy(Rainy) - �rac{4}{14} Entropy(Cloudy) I G ( W e a t h er ) = E n t ro p y ( Pl a y F oo t ba ll ) − 14 5 E n t ro p y ( S u nn y ) − 14 5 E n t ro p y ( R ain y ) − 14 4 E n t ro p y ( Cl o u d y ) I G ( W e a t h e r ) = 0.94 − 5 14 0.97 − 5 14 0.97 − 4 14 0 = 0.247 IG(Weather) = 0.94 - �rac{5}{14} 0.97 - �rac{5}{14} 0.97 - �rac{4}{14} 0 = 0.247 I G ( W e a t h er ) = 0.94 − 14 5 0.97 − 14 5 0.97 − 14 4 0 = 0.247 For Temperature: There are three unique values: Hot, Cool and Mild E n t r o p y o f H o t = − 2 4 l o g 2 2 4 − 2 4 l o g 2 2 4 = 1.0 Entropy,of,Hot=-�rac{2}{4}log_2�rac{2}{4}-�rac{2}{4}log_2�rac{2}{4} = 1.0 E n t ro p y o f Ho t = − 4 2 l o g 2 4 2 − 4 2 l o g 2 4 2 = 1.0 E n t r o p y o f C o o l = − 3 4 l o g 2 3 4 − 1 4 l o g 2 1 4 = 0.81 Entropy,of,Cool=-�rac{3}{4}log_2�rac{3}{4}-�rac{1}{4}log_2�rac{1}{4} = 0.81 E n t ro p y o f C oo l = − 4 3 l o g 2 4 3 − 4 1 l o g 2 4 1 = 0.81 E n t r o p y o f M i l d = − 4 6 l o g 2 4 6 − 2 6 l o g 2 2 6 = 0.918 Entropy,of,Mild=-�rac{4}{6}log_2�rac{4}{6}-�rac{2}{6}log_2�rac{2}{6} = 0.918 E n t ro p y o f M i l d = − 6 4 l o g 2 6 4 − 6 2 l o g 2 6 2 = 0.918 I G ( T e m p e r a t u r e ) = E n t r o p y ( P l a y F o o t b a l l ) − 4 14 E n t r o p y ( H o t ) − 4 14 E n t r o p y ( C o o l ) − 6 14 E n t r o p y ( M i l d ) IG(Temperature) = Entropy(Play Football) - �rac{4}{14} Entropy(Hot) - �rac{4}{14} Entropy(Cool) - �rac{6}{14} Entropy(Mild) I G ( T e m p er a t u re ) = E n t ro p y ( Pl a y F oo t ba ll ) − 14 4 E n t ro p y ( Ho t ) − 14 4 E n t ro p y ( C oo l ) − 14 6 E n t ro p y ( M i l d ) I G ( T e m p e r a t u r e ) = 0.94 − 4 14 1.0 − 4 14 0.81 − 6 14 0.918 = 0.03 IG(Temperature) = 0.94 - �rac{4}{14} 1.0 - �rac{4}{14} 0.81 - �rac{6}{14} 0.918 = 0.03 I G ( T e m p er a t u re ) = 0.94 − 14 4 1.0 − 14 4 0.81 − 14 6 0.918 = 0.03 For Humidity: There are two unique values: High and Normal E n t r o p y o f H i g h = − 3 7 l o g 2 3 7 − 4 7 l o g 2 4 7 = 0.98 Entropy,of,High=-�rac{3}{7}log_2�rac{3}{7}-�rac{4}{7}log_2�rac{4}{7} = 0.98 E n t ro p y o f H i g h = − 7 3 l o g 2 7 3 − 7 4 l o g 2 7 4 = 0.98 E n t r o p y o f N o r m a l = − 6 7 l o g 2 6 7 − 1 7 l o g 2 1 7 = 0.59 Entropy,of,Normal=-�rac{6}{7}log_2�rac{6}{7}-�rac{1}{7}log_2�rac{1}{7} = 0.59 E n t ro p y o f N or ma l = − 7 6 l o g 2 7 6 − 7 1 l o g 2 7 1 = 0.59 I G ( H u m i d i t y ) = E n t r o p y ( P l a y F o o t b a l l ) − 7 14 E n t r o p y ( H i g h ) − 7 14 E n t r o p y ( N o r m a l ) IG(Humidity) = Entropy(Play Football) - �rac{7}{14} Entropy(High) - �rac{7}{14} Entropy(Normal) I G ( H u mi d i t y ) = E n t ro p y ( Pl a y F oo t ba ll ) − 14 7 E n t ro p y ( H i g h ) − 14 7 E n t ro p y ( N or ma l ) I G ( H u m i d i t y ) = 0.94 − 7 14 0.98 − 7 14 0.59 = 0.15 IG(Humidity) = 0.94 - �rac{7}{14} 0.98 - �rac{7}{14} 0.59 = 0.15 I G ( H u mi d i t y ) = 0.94 − 14 7 0.98 − 14 7 0.59 = 0.15 For wind: There are two unique values: Weak and Strong E n t r o p y o f W e a k = − 3 6 l o g 2 3 6 − 3 6 l o g 2 3 6 = 1.0 Entropy,of,Weak=-�rac{3}{6}log_2�rac{3}{6}-�rac{3}{6}log_2�rac{3}{6} = 1.0 E n t ro p y o f W e ak = − 6 3 l o g 2 6 3 − 6 3 l o g 2 6 3 = 1.0 E n t r o p y o f S t r o n g = − 6 8 l o g 2 6 8 − 2 8 l o g 2 2 8 = 0.81 Entropy,of,Strong=-�rac{6}{8}log_2�rac{6}{8}-�rac{2}{8}log_2�rac{2}{8} = 0.81 E n t ro p y o f St ro n g = − 8 6 l o g 2 8 6 − 8 2 l o g 2 8 2 = 0.81 I G ( W i n d ) = E n t r o p y ( P l a y F o o t b a l l ) − 6 14 E n t r o p y ( W e a k ) − 8 14 E n t r o p y ( S t r o n g ) IG(Wind) = Entropy(Play Football) - �rac{6}{14} Entropy(Weak) - �rac{8}{14} Entropy(Strong) I G ( Win d ) = E n t ro p y ( Pl a y F oo t ba ll ) − 14 6 E n t ro p y ( W e ak ) − 14 8 E n t ro p y ( St ro n g ) I G ( W i n d ) = 0.94 − 6 14 1.0 − 8 14 0.81 = 0.05 IG(Wind) = 0.94 - �rac{6}{14} 1.0 - �rac{8}{14} 0.81 = 0.05 I G ( Win d ) = 0.94 − 14 6 1.0 − 14 8 0.81 = 0.05 Now that we have all the Information Gain Index, let's analyze them.
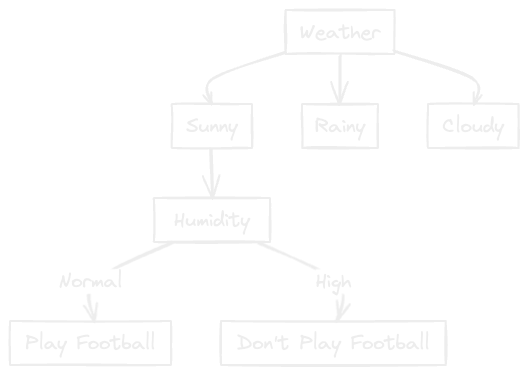
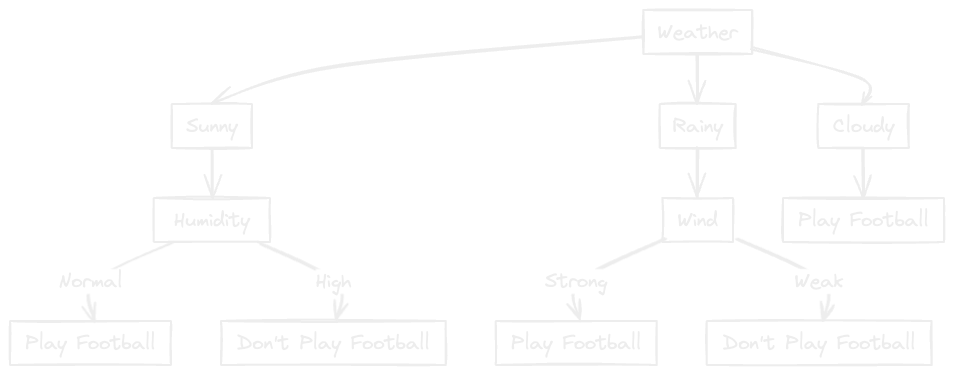
The highest Information Gain is to be selected as root node. In this case, it is Weather. Hence, the decision tree we get now is:
Now let's do the further processing for the "Sunny" Condition. Consider the following dataset:
E n t r o p y ( P l a y F o o t b a l l ) = − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 = 0.97 Entropy(Play Football) = -�rac{2}{5}log_2�rac{2}{5}-�rac{3}{5}log_2�rac{3}{5} = 0.97 E n t ro p y ( Pl a y F oo t ba ll ) = − 5 2 l o g 2 5 2 − 5 3 l o g 2 5 3 = 0.97 For Temperature: There are three values: Hot, Mild, Cool E n t r o p y f o r H o t = − 2 2 l o g 2 2 2 − 0 2 l o g 2 0 2 = 0 Entropy,for,Hot = -�rac{2}{2}log_2�rac{2}{2}-�rac{0}{2}log_2�rac{0}{2} = 0 E n t ro p y f or Ho t = − 2 2 l o g 2 2 2 − 2 0 l o g 2 2 0 = 0 E n t r o p y f o r M i l d = − 1 2 l o g 2 1 2 − 1 2 l o g 2 1 2 = 1.0 Entropy,for,Mild = -�rac{1}{2}log_2�rac{1}{2}-�rac{1}{2}log_2�rac{1}{2} = 1.0 E n t ro p y f or M i l d = − 2 1 l o g 2 2 1 − 2 1 l o g 2 2 1 = 1.0 E n t r o p y f o r C o o l = − 1 1 l o g 2 1 1 − 0 1 l o g 2 0 1 = 0 Entropy,for,Cool = -�rac{1}{1}log_2�rac{1}{1}-�rac{0}{1}log_2�rac{0}{1} = 0 E n t ro p y f or C oo l = − 1 1 l o g 2 1 1 − 1 0 l o g 2 1 0 = 0 I G ( T e m p e r a t u r e ) = E n t r o p y ( P l a y F o o t b a l l ) − 2 5 E n t r o p y ( H o t ) − 2 5 E n t r o p y ( M i l d ) − 1 5 E n t r o p y ( C o o l ) IG(Temperature) = Entropy(Play Football) - �rac{2}{5} Entropy(Hot) - �rac{2}{5} Entropy(Mild) - �rac{1}{5} Entropy(Cool) I G ( T e m p er a t u re ) = E n t ro p y ( Pl a y F oo t ba ll ) − 5 2 E n t ro p y ( Ho t ) − 5 2 E n t ro p y ( M i l d ) − 5 1 E n t ro p y ( C oo l ) I G ( T e m p e r a t u r e ) = 0.97 − 2 5 0 − 2 5 1.0 − 1 5 0 = 0.57 IG(Temperature) = 0.97 - �rac{2}{5} 0 - �rac{2}{5} 1.0 - �rac{1}{5} 0 = 0.57 I G ( T e m p er a t u re ) = 0.97 − 5 2 0 − 5 2 1.0 − 5 1 0 = 0.57 For Humidity: There are two values: High and Normal E n t r o p y f o r H i g h = − 3 3 l o g 2 3 3 − 0 3 l o g 2 0 3 = 0 Entropy,for,High = -�rac{3}{3}log_2�rac{3}{3}-�rac{0}{3}log_2�rac{0}{3} = 0 E n t ro p y f or H i g h = − 3 3 l o g 2 3 3 − 3 0 l o g 2 3 0 = 0 E n t r o p y f o r N o r m a l = − 0 2 l o g 2 0 2 − 2 2 l o g 2 2 2 = 0 Entropy,for,Normal = -�rac{0}{2}log_2�rac{0}{2}-�rac{2}{2}log_2�rac{2}{2} = 0 E n t ro p y f or N or ma l = − 2 0 l o g 2 2 0 − 2 2 l o g 2 2 2 = 0 I G ( H u m i d i t y ) = E n t r o p y ( P l a y F o o t b a l l ) − 3 5 E n t r o p y ( H i g h ) − 2 5 E n t r o p y ( N o r m a l ) IG(Humidity) = Entropy(Play Football) - �rac{3}{5} Entropy(High) - �rac{2}{5} Entropy(Normal) I G ( H u mi d i t y ) = E n t ro p y ( Pl a y F oo t ba ll ) − 5 3 E n t ro p y ( H i g h ) − 5 2 E n t ro p y ( N or ma l ) I G ( H u m i d i t y ) = 0.97 − 3 5 0 − 2 5 0 = 0.97 IG(Humidity) = 0.97 - �rac{3}{5} 0 - �rac{2}{5} 0 = 0.97 I G ( H u mi d i t y ) = 0.97 − 5 3 0 − 5 2 0 = 0.97 For Wind: There are two values: Weak and Strong E n t r o p y f o r W e a k = − 1 3 l o g 2 1 3 − 2 3 l o g 2 2 3 = 0.918 Entropy,for,Weak = -�rac{1}{3}log_2�rac{1}{3}-�rac{2}{3}log_2�rac{2}{3} = 0.918 E n t ro p y f or W e ak = − 3 1 l o g 2 3 1 − 3 2 l o g 2 3 2 = 0.918 E n t r o p y f o r S t r o n g = − 1 2 l o g 2 1 2 − 1 2 l o g 2 1 2 = 1.0 Entropy,for,Strong = -�rac{1}{2}log_2�rac{1}{2}-�rac{1}{2}log_2�rac{1}{2} = 1.0 E n t ro p y f or St ro n g = − 2 1 l o g 2 2 1 − 2 1 l o g 2 2 1 = 1.0 I G ( W i n d ) = E n t r o p y ( P l a y F o o t b a l l ) − 3 5 E n t r o p y ( W e a k ) − 2 5 E n t r o p y ( S t r o n g ) IG(Wind) = Entropy(Play Football) - �rac{3}{5} Entropy(Weak) - �rac{2}{5} Entropy(Strong) I G ( Win d ) = E n t ro p y ( Pl a y F oo t ba ll ) − 5 3 E n t ro p y ( W e ak ) − 5 2 E n t ro p y ( St ro n g ) I G ( W i n d ) = 0.97 − 3 5 0.918 − 2 5 1.0 = 0.02 IG(Wind) = 0.97 - �rac{3}{5} 0.918 - �rac{2}{5} 1.0 = 0.02 I G ( Win d ) = 0.97 − 5 3 0.918 − 5 2 1.0 = 0.02 Let's check all the Information Gain Indexes:
Since the highest is Humidity, the Humidity node comes after Sunny.
From the dataset, we can clearly notice that when Humidity is high, football is not played and when it is normal, football is played. Hence we can insert a leaf node or output node for this.
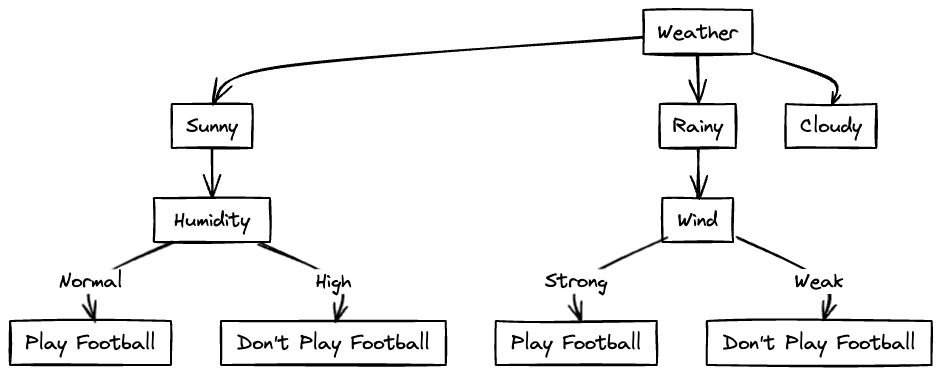
The resulting decision tree is as follows:
Now let's check the data for Rainy:
E n t r o p y ( P l a y F o o t b a l l ) = − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 = 0.97 Entropy(Play Football) = -�rac{2}{5}log_2�rac{2}{5}-�rac{3}{5}log_2�rac{3}{5} = 0.97 E n t ro p y ( Pl a y F oo t ba ll ) = − 5 2 l o g 2 5 2 − 5 3 l o g 2 5 3 = 0.97 For Temperature: There are two values: Mild, Cool E n t r o p y f o r M i l d = − 2 3 l o g 2 2 3 − 1 3 l o g 2 1 3 = 0.92 Entropy,for,Mild = -�rac{2}{3}log_2�rac{2}{3}-�rac{1}{3}log_2�rac{1}{3} = 0.92 E n t ro p y f or M i l d = − 3 2 l o g 2 3 2 − 3 1 l o g 2 3 1 = 0.92 E n t r o p y f o r C o o l = − 1 2 l o g 2 1 2 − 1 2 l o g 2 1 2 = 1.0 Entropy,for,Cool = -�rac{1}{2}log_2�rac{1}{2}-�rac{1}{2}log_2�rac{1}{2} = 1.0 E n t ro p y f or C oo l = − 2 1 l o g 2 2 1 − 2 1 l o g 2 2 1 = 1.0 I G ( T e m p e r a t u r e ) = E n t r o p y ( P l a y F o o t b a l l ) − 3 5 E n t r o p y ( M i l d ) − 2 5 E n t r o p y ( C o o l ) IG(Temperature) = Entropy(Play Football) - �rac{3}{5} Entropy(Mild) - �rac{2}{5} Entropy(Cool) I G ( T e m p er a t u re ) = E n t ro p y ( Pl a y F oo t ba ll ) − 5 3 E n t ro p y ( M i l d ) − 5 2 E n t ro p y ( C oo l ) I G ( T e m p e r a t u r e ) = 0.97 − 3 5 0.92 − 2 5 1.0 = 0.02 IG(Temperature) = 0.97 - �rac{3}{5} 0.92 - �rac{2}{5} 1.0 = 0.02 I G ( T e m p er a t u re ) = 0.97 − 5 3 0.92 − 5 2 1.0 = 0.02 For Humidity: There are two values: High and Normal E n t r o p y f o r H i g h = − 1 2 l o g 2 1 2 − 1 2 l o g 2 1 2 = 1.0 Entropy,for,High = -�rac{1}{2}log_2�rac{1}{2}-�rac{1}{2}log_2�rac{1}{2} = 1.0 E n t ro p y f or H i g h = − 2 1 l o g 2 2 1 − 2 1 l o g 2 2 1 = 1.0 E n t r o p y f o r N o r m a l = − 2 3 l o g 2 2 3 − 1 3 l o g 2 1 3 = 0.92 Entropy,for,Normal = -�rac{2}{3}log_2�rac{2}{3}-�rac{1}{3}log_2�rac{1}{3} = 0.92 E n t ro p y f or N or ma l = − 3 2 l o g 2 3 2 − 3 1 l o g 2 3 1 = 0.92 I G ( H u m i d i t y ) = E n t r o p y ( P l a y F o o t b a l l ) − 2 5 E n t r o p y ( H i g h ) − 3 5 E n t r o p y ( N o r m a l ) IG(Humidity) = Entropy(Play Football) - �rac{2}{5} Entropy(High) - �rac{3}{5} Entropy(Normal) I G ( H u mi d i t y ) = E n t ro p y ( Pl a y F oo t ba ll ) − 5 2 E n t ro p y ( H i g h ) − 5 3 E n t ro p y ( N or ma l ) I G ( H u m i d i t y ) = 0.97 − 2 5 1.0 − 3 5 0.92 = 0.02 IG(Humidity) = 0.97 - �rac{2}{5} 1.0 - �rac{3}{5} 0.92 = 0.02 I G ( H u mi d i t y ) = 0.97 − 5 2 1.0 − 5 3 0.92 = 0.02 For Wind: There are two values: Weak and Strong E n t r o p y f o r W e a k = − 3 3 l o g 2 3 3 − 0 3 l o g 2 0 3 = 0 Entropy,for,Weak = -�rac{3}{3}log_2�rac{3}{3}-�rac{0}{3}log_2�rac{0}{3} = 0 E n t ro p y f or W e ak = − 3 3 l o g 2 3 3 − 3 0 l o g 2 3 0 = 0 E n t r o p y f o r S t r o n g = − 2 2 l o g 2 2 2 − 2 2 l o g 2 2 2 = 0 Entropy,for,Strong = -�rac{2}{2}log_2�rac{2}{2}-�rac{2}{2}log_2�rac{2}{2} = 0 E n t ro p y f or St ro n g = − 2 2 l o g 2 2 2 − 2 2 l o g 2 2 2 = 0 I G ( W i n d ) = E n t r o p y ( P l a y F o o t b a l l ) − 3 5 E n t r o p y ( W e a k ) − 2 5 E n t r o p y ( S t r o n g ) IG(Wind) = Entropy(Play Football) - �rac{3}{5} Entropy(Weak) - �rac{2}{5} Entropy(Strong) I G ( Win d ) = E n t ro p y ( Pl a y F oo t ba ll ) − 5 3 E n t ro p y ( W e ak ) − 5 2 E n t ro p y ( St ro n g ) I G ( W i n d ) = 0.97 − 3 5 0 − 2 5 0 = 0.97 IG(Wind) = 0.97 - �rac{3}{5} 0 - �rac{2}{5} 0 = 0.97 I G ( Win d ) = 0.97 − 5 3 0 − 5 2 0 = 0.97 Let's check all the Information Gain Indexes:
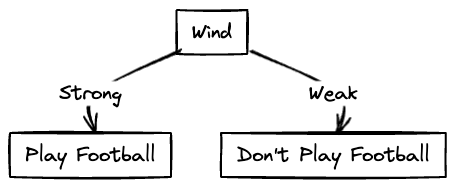
Since the highest is Wind, the Wind node comes after Rainy.
It can be seen that when Wind is Strong, football is not played and when it is Weak, football is played. Hence we can insert a leaf node or output node for this.
The resulting decision tree is as follows:
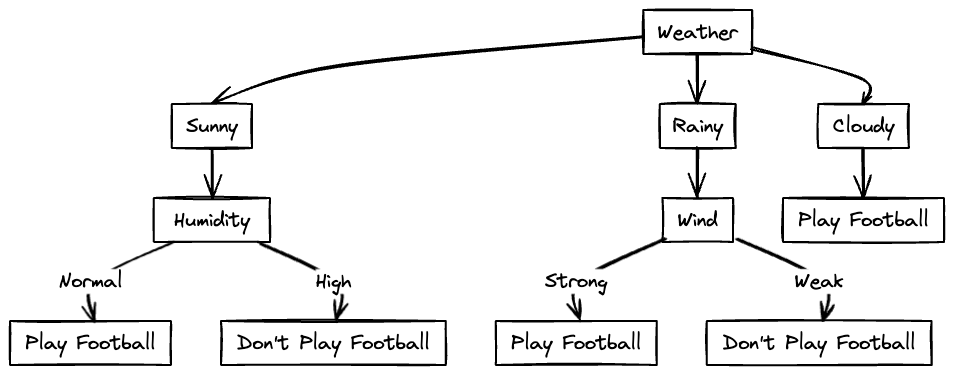
Now let's look at the data for cloudy weather!
We can see that all the labels are "Yes" in this data. Hence we can conclude that for cloudy weather, football will be played regardless of temperature, humidity and wind.
The final decision tree constructed will be as follows:
Decision Tree Classifier: Gini Index Method Gini index is very similar to Information Gain Index. Here are the equations and steps with respect to Gini-Index Method. Gini Index is a more powerful measure of entropy in datasets and is hence proven to be more effective than Information Gain.
Step 1: Calculate Gini-Index of each Feature Column G i n i I n d e x o f U n i q u e V a l u e = 1 − ∑ c l a s s = 1 n p ( c l a s s ) 2 Gini,Index,of,UniqueValue =1 - sum_{class=1}^{n}p(class)^2 G ini I n d e x o f U ni q u e Va l u e = 1 − c l a ss = 1 ∑ n p ( c l a ss ) 2 W h e r e p ( c l a s s ) = N u m b e r o f s a m p l e s c o r r e s p o n d i n g t o t h e c l a s s a n d s e l e c t e d f e a t u r e v a l u e T o t a l n u m b e r o f s a m p l e s Where;p(class) = �rac{Number,of,samples,corresponding,to,the,class,and,selected,feature,value}{Total,number,of,samples} Wh ere p ( c l a ss ) = T o t a l n u mb er o f s am pl es N u mb er o f s am pl es corres p o n d in g t o t h e c l a ss an d se l ec t e d f e a t u re v a l u e After calculating the entropy for each unique value in the feature column, next step is to calculate the entropy of the feature column using the following arithmetic equation:
E n t r o p y o f F e a t u r e = ∑ U n i q u e V a l = 1 n p ( U n i q u e V a l ) . G i n i I n d e x o f U n i q u e V a l Entropy,of,Feature = sum_{UniqueVal=1}^n p(UniqueVal) . Gini,Index,of,UniqueVal E n t ro p y o f F e a t u re = U ni q u e Va l = 1 ∑ n p ( U ni q u e Va l ) . G ini I n d e x o f U ni q u e Va l W h e r e p ( c l a s s ) = N u m b e r o f s a m p l e s c o r r e s p o n d i n g t o t h e U n i q u e V a l T o t a l n u m b e r o f s a m p l e s Where;p(class) = �rac{Number,of,samples,corresponding,to,the,UniqueVal}{Total,number,of,samples} Wh ere p ( c l a ss ) = T o t a l n u mb er o f s am pl es N u mb er o f s am pl es corres p o n d in g t o t h e U ni q u e Va l Repeat this process for each feature column.
Step 2: Select the Attribute with Lowest Gini-Index as Decision Node The feature with lowest gini-index is utilized as the decision node and the process is repeated until leaf node is achieved.
Working Example Consider the following data:
For Temperature: There are 3 values: Hot, Mild and Cool G i n i ( H o t ) = 1 − p ( Y e s ) 2 − p ( N o ) 2 Gini(Hot) = 1 - p(Yes)^2 - p(No)^2 G ini ( Ho t ) = 1 − p ( Y es ) 2 − p ( N o ) 2 G i n i ( H o t ) = 1 − ( 0 2 ) 2 − ( 2 2 ) 2 = 0 Gini(Hot) = 1 - (�rac{0}{2})^2 - (�rac{2}{2})^2 = 0 G ini ( Ho t ) = 1 − ( 2 0 ) 2 − ( 2 2 ) 2 = 0 G i n i ( M i l d ) = 1 − ( 1 2 ) 2 − ( 1 2 ) 2 = 0.5 Gini(Mild) = 1 - (�rac{1}{2})^2 - (�rac{1}{2})^2 = 0.5 G ini ( M i l d ) = 1 − ( 2 1 ) 2 − ( 2 1 ) 2 = 0.5 G i n i ( C o o l ) = 1 − ( 1 1 ) 2 − ( 0 1 ) 2 = 0 Gini(Cool) = 1 - (�rac{1}{1})^2 - (�rac{0}{1})^2 = 0 G ini ( C oo l ) = 1 − ( 1 1 ) 2 − ( 1 0 ) 2 = 0 G i n i ( T e m p e r a t u r e ) = 2 5 0 + 2 5 0.5 + 1 5 0 = 0.2 Gini(Temperature) = �rac{2}{5} 0 + �rac{2}{5}0.5 + �rac{1}{5}0 = 0.2 G ini ( T e m p er a t u re ) = 5 2 0 + 5 2 0.5 + 5 1 0 = 0.2 For Humidity: There are two values: High and Normal G i n i ( H i g h ) = 1 − ( 0 3 ) 2 − ( 3 3 ) 2 = 0 Gini(High) = 1 - (�rac{0}{3})^2 - (�rac{3}{3})^2 = 0 G ini ( H i g h ) = 1 − ( 3 0 ) 2 − ( 3 3 ) 2 = 0 G i n i ( N o r m a l ) = 1 − ( 2 2 ) 2 − ( 0 2 ) 2 = 0 Gini(Normal) = 1 - (�rac{2}{2})^2 - (�rac{0}{2})^2 = 0 G ini ( N or ma l ) = 1 − ( 2 2 ) 2 − ( 2 0 ) 2 = 0 G i n i ( H u m i d i t y ) = 3 5 0 + 2 5 0 = 0 Gini(Humidity) = �rac{3}{5} 0 + �rac{2}{5}0 = 0 G ini ( H u mi d i t y ) = 5 3 0 + 5 2 0 = 0 For Wind: There are two values: Weak and Strong G i n i ( W e a k ) = 1 − ( 1 3 ) 2 − ( 2 3 ) 2 = 0.44 Gini(Weak) = 1 - (�rac{1}{3})^2 - (�rac{2}{3})^2 = 0.44 G ini ( W e ak ) = 1 − ( 3 1 ) 2 − ( 3 2 ) 2 = 0.44 G i n i ( S t r o n g ) = 1 − ( 1 2 ) 2 − ( 1 2 ) 2 = 0.5 Gini(Strong) = 1 - (�rac{1}{2})^2 - (�rac{1}{2})^2 = 0.5 G ini ( St ro n g ) = 1 − ( 2 1 ) 2 − ( 2 1 ) 2 = 0.5 G i n i ( W i n d ) = 3 5 0.44 + 2 5 0.5 = 0.464 Gini(Wind) = �rac{3}{5} 0.44 + �rac{2}{5} 0.5 = 0.464 G ini ( Win d ) = 5 3 0.44 + 5 2 0.5 = 0.464 The lowest Gini Index is of Humidity. Therefore Humidity is selected as decision node.
Therefore the tree that is formed is:
Python Implementation of Decision Tree Classifier Following is the Python code for decision tree classifier:
# Import Required Modules from sklearn . tree import DecisionTreeClassifier from sklearn import tree from sklearn . metrics import confusion_matrix , ConfusionMatrixDisplay import pandas as pd import matplotlib . pyplot as plt
# Data Reading Pre-Processing data = pd . read_excel ( " data.xlsx " ) data [ ' Weather ' ]. replace ([ ' Sunny ' , ' Rainy ' , ' Cloudy ' ], [ 0 , 1 , 2 ], inplace = True ) data [ ' Temperature ' ]. replace ([ ' Hot ' , ' Cool ' , ' Mild ' ], [ 0 , 1 , 2 ], inplace = True ) data [ ' Humidity ' ]. replace ([ ' High ' , ' Normal ' ], [ 0 , 1 ], inplace = True ) data [ ' Wind ' ]. replace ([ ' Weak ' , ' Strong ' ], [ 0 , 1 ], inplace = True ) data [ ' Play Football ' ]. replace ([ ' No ' , ' Yes ' ], [ 0 , 1 ], inplace = True )
# Separating Features and Label x = data . drop ( " Play Football " , axis = 1 ) y = data [[ " Play Football " ]]
# Model Training model = DecisionTreeClassifier () model . fit ( x , y )
# Confusion Matrix cm = confusion_matrix ( y , model . predict ( x )) ConfusionMatrixDisplay ( cm ). plot ()
# Append predicted values to data to display data = pd . read_excel ( " data.xlsx " ) data [ " Model Predictions " ] = model . predict ( x ) data [ ' Model Predictions ' ]. replace ([ 0 , 1 ], [ " No " , " Yes " ], inplace = True ) # Import Required Modules from sklearn . tree import DecisionTreeClassifier from sklearn import tree from sklearn . metrics import confusion_matrix , ConfusionMatrixDisplay import pandas as pd import matplotlib . pyplot as plt
# Data Reading Pre-Processing data = pd . read_excel ( "data.xlsx" ) data [ 'Weather' ]. replace ([ 'Sunny' , 'Rainy' , 'Cloudy' ], [ 0 , 1 , 2 ], inplace = True ) data [ 'Temperature' ]. replace ([ 'Hot' , 'Cool' , 'Mild' ], [ 0 , 1 , 2 ], inplace = True ) data [ 'Humidity' ]. replace ([ 'High' , 'Normal' ], [ 0 , 1 ], inplace = True ) data [ 'Wind' ]. replace ([ 'Weak' , 'Strong' ], [ 0 , 1 ], inplace = True ) data [ 'Play Football' ]. replace ([ 'No' , 'Yes' ], [ 0 , 1 ], inplace = True )
# Separating Features and Label x = data . drop ( "Play Football" , axis = 1 ) y = data [ [ "Play Football" ] ]
# Model Training model = DecisionTreeClassifier () model . fit (x, y)
# Confusion Matrix cm = confusion_matrix (y, model. predict (x)) ConfusionMatrixDisplay (cm). plot ()
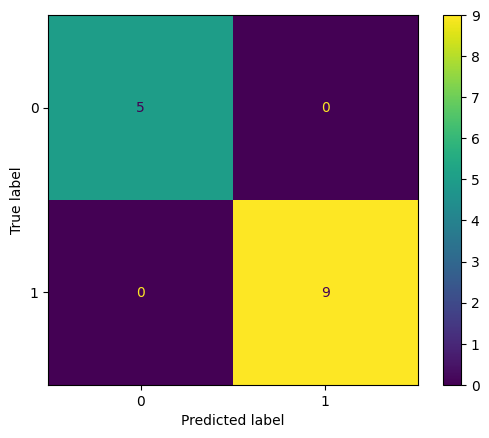
# Append predicted values to data to display data = pd . read_excel ( "data.xlsx" ) data [ "Model Predictions" ] = model . predict (x) data [ 'Model Predictions' ]. replace ([ 0 , 1 ], [ "No" , "Yes" ], inplace = True ) The Confusion Matrix produced by this code is as follows:
Confusion Matrix
It can be interpreted by this confusion matrix that all the predictions were accurate and there were 5 true negatives and 9 true positives.
This is all about the Decision Tree Classifier. If you have any questions regarding this, feel free to contact me.
Up next, we have the Decision Tree Regressor where we train the Decision Tree Algorithm to work with continuous values. Stay Tuned!